HtmlCleaner
這篇文章是為了解決這篇回應遇到的問題,想說寫下來方便其他遇到同樣問題的人可以參考。使用的工具
HtmlCleaner請將 HtmlCleaner 官網中下載的 *.jar 檔加入專案中的 libs 目錄。
程式碼
用來儲存資料的值物件,Price.java
public class Price {
/**
* 按盤價
*/
private String priceNow;
/**
* 最高
*/
private String highest;
/**
* 最低
*/
private String lowest;
public String getPriceNow() {
return priceNow;
}
public void setPriceNow(String priceNow) {
this.priceNow = priceNow;
}
public String getHighest() {
return highest;
}
public void setHighest(String highest) {
this.highest = highest;
}
public String getLowest() {
return lowest;
}
public void setLowest(String lowest) {
this.lowest = lowest;
}
}工具類別,Utility.java
public class Utility {
public static final String DATA_URL = "http://www.etnet.com.hk/mobile/tc/quote.php?code=";
/**
* Get method
* @param _url
* @return
*/
public static String getHtmlByGet(String _url){
String result = "";
DefaultHttpClient client = new DefaultHttpClient();
try {
HttpGet get = new HttpGet(_url);
HttpResponse response = client.execute(get);
HttpEntity resEntity = response.getEntity();
if (resEntity != null) {
result = toUTF8(resEntity.getContent());
}
} catch (Exception e) {
e.printStackTrace();
} finally {
client.getConnectionManager().shutdown();
}
return result;
}
/**
* 取得即時報價
* @param code
*/
public static Price getPrice(String code){
Price price = new Price();
String html = getHtmlByGet(DATA_URL + code);
TagNode tagNode;
try {
tagNode = new HtmlCleaner().clean(html);
//按盤價
TagNode[] nodePriceNow = tagNode.getElementsByAttValue("class", "quoteNominalRight bigdown2", true, false);
String priceNow = nodePriceNow[0].getText().toString();
price.setPriceNow(priceNow);
TagNode[] nodeQuoteOther = tagNode.getElementsByAttValue("class", "quoteOther", true, false);
String highest = nodeQuoteOther[1].getText().toString();
String lowest = nodeQuoteOther[3].getText().toString();
price.setHighest(highest);
price.setLowest(lowest);
} catch (Exception e) {
e.printStackTrace();
}
return price;
}
private static String toUTF8(InputStream is){
//InputStream is = resEntity.getContent();
InputStreamReader isr = null;
StringBuffer buffer = new StringBuffer();
try {
isr = new InputStreamReader(is, "utf-8");
Reader in = new BufferedReader(isr);
int ch;
while((ch = in.read()) != -1){
buffer.append((char)ch);
}
isr.close();
is.close();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e){
e.printStackTrace();
}
return buffer.toString();
}
}執行 MainActivity.java
public class MainActivity extends Activity {
private TextView txtResult;
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
initView();
getData();
}
private void initView() {
txtResult = (TextView) findViewById(R.id.txtResult);
}
private void getData() {
Price price = Utility.getPrice("1");
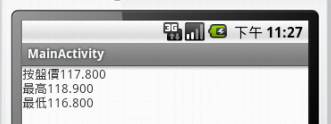
String result = "按盤價" + price.getPriceNow() + "\n最高" + price.getHighest() + "\n最低" + price.getLowest();
txtResult.setText(result);
}
}執行結果
 因為隨手寫的,所以可能會有誤,直接下載程式碼回去研究吧。
因為隨手寫的,所以可能會有誤,直接下載程式碼回去研究吧。程式碼下載:HtmlParserDemo.zip
本文網址:http://blog.tonycube.com/2012/10/androidhtml-parserhtmlcleaner.html
由 Tony Blog 撰寫,請勿全文複製,轉載時請註明出處及連結,謝謝 😀
由 Tony Blog 撰寫,請勿全文複製,轉載時請註明出處及連結,謝謝 😀
HtmlCleaner
回覆刪除請將 *.jar 檔加入專案中的 libs 目錄。
是什麼意思
然後載了程式用了發現
模擬器上面的數值跟網頁上面的數值不太一樣
是延遲的關係嗎?
*.jar 是指在 HtmlCleaner 官網的 Download 頁面下載的 htmlcleaner-2.2.jar 檔
刪除libs 是指 Android 專案的一個目錄,你要把 htmlcleaner-2.2.jar 複製到 libs 目錄中
數值不同一定是網頁的資料在程式下載後有更新過,不然不會不一樣
下載了範例可以成功的RUN起來,
回覆刪除但是收不到值的部份,看過網址也沒有掛掉,
值的部份回傳都是NULL值,想請問原因為何...
屬性名稱改變了,所以抓不到資料。它的名稱會因為上漲或下跌而改變,所以我這個例子寫的不好,當初趕出來的沒研究,反正是範例。
刪除重點是,
tagNode.getElementsByAttValue("class", "quoteNominalRight bigdown2", true, false);
第1個參數是html的屬性名稱,第2個是該名稱的值,在html中看起來是
class="quoteNominalRight bigdown2"
所以這樣你應該知道怎麼辦了吧~~
自行研究一下 getXXX 方法吧,有可以抓屬性的值,也有以標籤名稱去抓的,
API文件在此,看完 TagNode 類別,你就會功力大增了~
http://htmlcleaner.sourceforge.net/doc/index.html
不好意思,關於板大的這個解答..
刪除小妹專研了很久後仍舊不是很懂(超級初學者><
所以說getElementsByAttValue是會先找到"class"然後再進一步抓到"quoteNominalRight bigdown2",所以範例中會顯示NULL,是因為它的class名稱改變了?
只是class應該是不會改變的壓?0.0
(我將網址換成了其他網站的網址,
並且將相對應的屬性名稱修改了,但是結果仍舊是顯示NULL
還是說,
必須要修改agNode.getElementsByAttValue成其他get方法呢?><
麻煩大哥幫忙解惑一下OAQ 謝謝!!!><
HtmlCleaner 這個工具的運作是,
刪除讀取整個網頁->解析HTML標籤->組成DOM樹,
所以當你
tagNode.getElementsByAttValue("class", "quoteNominalRight bigdown2", true, false);
的時候,
它會對所有包含class屬性的標籤瀏覽比對其值是否為"quoteNominalRight bigdown2",
(這個網站的該標籤的屬性值class是會變的,依上漲或下跌而變,另一是".......bigup2")
=======================
測其他網址前先看看html有沒有抓正確,這行
String html = getHtmlByGet(DATA_URL + code);
會取得html,
把該字串直接顯示在txtResult裡面,看看你要找的class在不在,
或是單純一點,直接抓標籤就好
tagNode.getElementsByName("p", true);
上正這行會去抓所有的〈p〉〈/p〉
TODO check:
1.確定抓到的html是否正確
2.確定要取得的標籤或屬性是否存在
先感謝大哥,總算是對HtmlCleaner有點了解了><
刪除但想請問大哥,我將Utility.java中的網址改成:
public class Utility {
public static final String DATA_URL = "http://www.ipeen.com.tw/shop/";
並且將MainActivity.java中的getPrice
改成欲擷取資訊中的其中一個網頁代碼(範例中原先是"1"):
private void getData() {
Price price = Utility.getPrice("35535");
String result = "店名" + price.getPriceNow() + "\n電話" + price.getHighest() + "\n住址" + price.getLowest();
txtResult.setText(result);
}
而在屬性中指定部分,改成:
TagNode[] nodePriceNow = tagNode.getElementsByAttValue("class", "de_name", true, false);
----------------------------------------
但是顯示出來仍舊是NULLˊˋ
有檢查過大哥提出的兩項了,但是實在是看不出html和屬性有任何錯誤OAQ
所以,想要請教幾個問題:
1. 當我欲抓取class="de_name"中的資料時,從原始碼中可以看到de_name被指定在很多不同的資料中(ex,商店名稱、電話、店址等等),那這樣要如何讓程式知道,我所要parser的資料是哪些部分呢?
2. 倘若在程式可以正常執行的情況下,當我指定
Price price = Utility.getPrice("35535");時,
系統會抓取到http://www.ipeen.com.tw/shop/35535中我所指定的資料,所以若要讓系統自動去抓取這個網站中每一筆美食資訊時,我必須要在自己寫一段程式碼,讓系統自動加數字,以達到「自動進入每一筆html」的目的囉?
3. 最後,關於我修改的程式碼的部分,想要請大哥幫我解答一下,所以再抓取html或是取得屬性的部分,是不是我哪裡疏忽了或是概念錯誤呢?><
初寫程式,問題很多,如果大哥不嫌棄的話,就麻煩了!!!感激不盡!!!(跪
我會繼續到處爬文和練習,打擾之處還請見諒..
1.nodePriceNow會是一個陣列,所以多個"de_name"就必須自己決定要取第幾筆資料。建議你還是先自己打造一個單純的網頁,先練習怎麼用。
刪除2.沒錯。但這是營業性網站,抓資料來用可能會違法,你應該有看到網頁最下面那行紅色的字吧,但願你只是練習。
3.錯誤的部份是發生在網址有中文,它的實際網址會轉為含有商店名稱的網址,DDMS上的錯誤訊息是"Illegal character in path at ....",所以在抓html時就發生錯誤了,後面怎麼解析也沒用。
發生錯誤時請先切斷你的執行步驟:
1.抓html
2.解析html
3.顯示資料
在任何步驟沒有正確之前就不要進到下個步驟,將抓到的html顯示出來,如果和你在瀏覽器看的網頁原始碼不同,就不要往下做,先解決這步驟,依此類推。
大哥您好,
回覆刪除我現在已經可以抓取網頁資料了,
可是在抓取這個網站時:
http://www.319papago.idv.tw/SuperTaste/700-E.html
卻無法抓取資料ˊˋ,想要請問一下是不是因為結尾是.html的關係呢?
還是有其他問題呢?0.0
另外,想要再請問大哥,
如果我要抓取網站中table裡的資料時,
要如何去抓取呢?><
已經有上網查詢過很多方法,但是還是無法成功ˊˋ
以上,謝謝大哥的解惑!!!OAQ
和html沒有關係,理論上應該可以抓到資料。
刪除1.分析資料
[1]打開"網頁源始碼",搜尋 "<table" 你會發現有4個table,你要的是在第4個。
[2]在[1]的 table 中取得每列的 tr
[3]在[2]的每個 td 就是你要的資料
2.實作
[1]tagNode.getElementsByName 去取 table 標籤陣列,然後只拿第4筆來用。
[2]tagNode.getElementsByName 取 tr 陣列
[3]tagNode.getElementsByName 取 td 陣列,即得每個欄位的資料
你好,剛好我也正在練習如何parser資料
刪除努力的嘗試了上面各位大大的做法
但當我嘗試練習到上面方同學所發問的網站時,我也碰到相同問題http://www.319papago.idv.tw/SuperTaste/700-E.html
這個網站,會一直跑出null耶@@
請問強大的Tony大大,這會是因為原始網頁程式碼有什麼保護措施之類的嗎?
我的做法是:
1.打開原始碼,搜尋class="style34",第一筆為:
class="style34" 食尚玩家美食總整理-台南市中西區
2.於是我按照大大的做法改成這樣:
TagNode[]nodePriceNow=tagNode.getElementsByAttValue("class", "style34", true, false);
tring priceNow = nodePriceNow[0].getText().toString();
最後發現他跑出null值>< 我常是很多不同標籤,好像都不行
----------------------------------------------------
初學者我還有一個小提問><
我有去練習看大大po的API文件,有些還看不太懂><
想請教Tony大大,您上面說的:
[1]tagNode.getElementsByName 去取table標籤陣列,然後只拿第4筆來用。
[2]tagNode.getElementsByName 取 tr 陣列
[3]tagNode.getElementsByName 取 td 陣列,即得每個欄位的資料
這個方法,是要寫判讀嗎?0.0
是要寫說當我取得第四筆table的標籤陣列時,再去執行取得tr陣列,最後再取得td陣列,然後td陣列就看我要娶幾筆資料而定義我的node[]數嗎?><
這部分我有一點小迷惑,還請大大包容並給予解惑
感謝您 :)
網站一直跑出null的問題我也不知道,
刪除取table不用判斷,就是第4個,所以前面3個就不理它,
之後的tr,td就用迴圈去跑,然後針對td的欄位 getText().toString()
就可取到該欄位的文字。
作者已經移除這則留言。
回覆刪除好像4.0以上(包含4.0)不支援是不是...
回覆刪除我用4.0之下的模擬器+手機能拿到資料
同樣程式碼
4.0以上就會NULL,連html那裡也是拿到NULL
樓上那些人的問題大概是這裡~
不過我也不知道解決方法:|
android 4.0以上好像不支援HtmlCleaner的樣子...
回覆刪除我使用2.3.3的模擬器或手機都能順利取得資料
使用4.0、4.1的模擬器或手機卻都取得NULL...
看來上面幾位的問題因該就是這個了:|
不過我也找不到解決方法==
感謝您的分享。
刪除應該不是HtmlCleaner的問題,可能是出在Java版本的問題,因為HtmlCleaner只做parser的動作,下載html是使用Java原本的網路功能,而會Null,是出在下載網頁這段。
之前有人碰過同樣的問題,在這篇
http://blog.tonycube.com/2011/11/androidsqlite.html
之下的某個回應中,當時找到的原因是JDK版本的問題,從1.7版降回1.6版就可以了。
看起來會Null可能和JDK版本有關,在stackoverflow有看到類似問題,Android 3.x之前的編譯都正常,但一編譯到4.x的就出問題。
發現問題摟~~
刪除Android 4.0 (ICS)在網路的部份多了一個新的Exception
叫做android.os.NetworkOnMainThreadException
意思很白話的就是:網路的活動跑在主要執行緒上了啦!
ICS很貼心的告訴你,這樣子你的APP可能會因為等待回應太久(超過5秒)
而會被系統強制關閉(收到ANR)
以上CO自網路,應該改成多執行緒的寫法就能順利擷取到資料不會NULL了~~
OK~~感謝您的分享~~~
刪除您好,目前也在撰寫這方面的相關作業,因為目前使用手機為4.0.3的系統
回覆刪除經過測試試讀到null的
而2.3.3的模擬機則可以順利的取出資料。
上面一樓的回答中提到應該是ICS的機制關係,所以我是要將與網路連線的部分都寫到另外一個執行緒下執行嗎?
有無相關的資源可以查看呢?
餵給Google神 Htmlcleaner android 4.0 找不太到相關討論串...
謝謝 :)
是的,重點就是不要把程式碼放在主執行緒中,
刪除那意思就是要生出另一個執行緒讓這些程式碼跑,
你可以自己寫 Thread 去 Run,
或是使用 Android 提供的 AsyncTask 會比較容易使用,
請參考 http://blog.tonycube.com/2011/08/asynctask.html
作者已經移除這則留言。
回覆刪除TONY大大 問您一下喔
回覆刪除我們現在專題正在製作微笑單車
我要能夠從他們的網站上抓取他們車輛空位的資訊
也能用這個做嗎@@?
可以。
刪除我本來想請你用open data,直接取資料比較方便,結果我怎麼查都找不到,就算了,反正資料只有一頁。
作者已經移除這則留言。
回覆刪除要抓哪個網站的資料,當然就要改成它的網址。
刪除至於"quoteNominalRight bigdown2 改為 estd"是因為有個標籤,它有個屬性class且它的值是estd,這樣就會取得符合的所有標籤,如果你只改這個值,但後面的程式碼都沒改,是一定出錯,因為兩個網頁是不同的。
看方法名稱 getElementsByAttValue() 就可以知到,它是由屬性值(AttValue)來取元素(Elements),之後會重覆這些動作,一層一層去取得資料,所以你要先去研究網頁的原始碼,看它的架構來依序取得你要的元素。
成功了 感謝 ~
刪除Tony大大,不好意思喔 我每次用你的範例檔
回覆刪除都沒辦法正常的執行耶,可是在學校用是正常的
這樣會是什麼問題啊?
範例我都是測試過才放上去的,應該是不會有問題。會出問題通常是"環境",例如Java版本、Eclipse版本(含外掛)、使用的Android SDK版本等等都可能因為不同而發生無法執行,當然也要確定能連到該網站才行。
刪除喔喔 大大謝謝你喔^^ 不好意思再問你一下 有辦法使用eclipse 抓取mysql內的資料嗎?或是可以使用csv檔
刪除正名一下:
刪除eclipse 是編輯器
MySQL 是資料庫伺服器
所以你的意思應該是 Java(Android) 去取 MySQL 伺服器中的資料?
因為 Android 並沒有內建 MySQL (而是 Sqlite) ,所以你必須透過網頁伺器去下取資料,
Android App <-> Web Server <-> MySQL
可以參考 http://seanstar5317.pixnet.net/blog/post/28092031-%5Bandroid%5D%E5%BE%9Emysql-%E6%8A%93%E8%B3%87%E6%96%99%EF%BC%8C%E5%8B%95%E6%85%8B%E6%96%B0%E5%A2%9Etextview%E8%87%B3tablela
csv 檔只是個純文字檔,用一般讀檔方式讀取後,依分隔字元(通常是逗號)來切出資料,可以參考
http://nkeegamedev.blogspot.tw/2012/07/android-csv.html
大大不好意思喔 問你一下 在你第2個給我的那個 我把他的程式碼抓下來丟到eclipse上 再把全部import上去
刪除最後就剩下txtview.setText(sb.toString());
這段,旁邊是寫上txtview cannot be resolved
我不知道該怎麼處理,謝謝
1.檢查看看 layout 的 xml 中的 TextView 名稱是否為 txtview(要和你程式碼中的R.id.txtview 相同)
刪除2.檢查 import 是否有 com.xxx.xxxx.R (就是你的 Package 名稱後面有R),
而不是 android.R
3.執行 Eclipse 選單 Project -> Clean 把專案清除後重新 Build
tony大大,這些方法我都試過了可是還是不行耶
刪除1. android:id="@+id/txtview" 他說的應該是這條吧
2.package com.example.comebike; 好像沒有出現R@@
1.那 layout 的 xml 就沒有問題
刪除2.如果你的 package 是 com.example.comebike
那你要看 import 裡有沒有 import com.example.comebike.R
這個表示它是參照你的 xml 去取得元件,
如果出現 android.R 是去參照 Android 系統本身,
那就會出現錯誤,因為在 android.R 裡面找不到 txtview
所以如果有看到 import android.R 把它刪掉,改為加入
import com.example.comebike.R
應該就會正常了,記得 Clean 專案。
tony大大 我的裡面沒有
刪除import com.example.comebike.R
也沒有 import android.R
大大對不起阿~"~小弟愚笨一直發問
如果沒有 import com.example.comebike.R 那就一定不能取得參照啊,
刪除自己加進去看看。記得 Clean 專案
tony大大 加進去之後 結果還是一樣@@
刪除你好 Tony大大
回覆刪除我也是Android開發新手
想請問
我剛下載並測試了程式
安裝在2.1版本或4.1版本的手機時都出現以下三個地方程式碼錯誤
無法正常啟動
at com.example.htmlpaserdemo.Utility.getPrice(Utility.java:70)
→"tagNode = new HtmlCleaner().clean(html);"
at com.example.htmlpaserdemo.MainActivity.getData(MainActivity.java:25)
→"Price price = Utility.getPrice("1");"
at com.example.htmlpaserdemo.MainActivity.onCreate(MainActivity.java:17)
→"getData();"
但不知問題出在哪 或如何更改
懇請該如何解決
Thank you
你把 String html = getHtmlByGet(DATA_URL + code); 這行之後的程式碼註解掉,然後把 html 印出來,看有沒有資料。
刪除你的 SDK 如果是API 11(Android 3.0)之後的,要把 getData() 從 onCreate 中移到另一個執行緒去執行。
測試 String html = getHtmlByGet(DATA_URL + code); 這行之後的程式註解後
刪除html印出的資料為網頁的程式碼內容
請問大大接下來如何修改呢?
刪除另外想請問上面所說的
弱勢API11以後的SDK
getData() 從 onCreate 中移到另一個執行緒去執行
不太了解如何做
如果有印出網頁原始碼,那
刪除at com.example.htmlpaserdemo.Utility.getPrice(Utility.java:70)
→"tagNode = new HtmlCleaner().clean(html);"
這行應該不會有錯才對,要在找看看是什麼問題。
移到另一個執行緒的做法,你可以看這篇
http://blog.tonycube.com/2011/11/androidget-post.html
最後面的補充,主要是使用 AsyncTask (http://blog.tonycube.com/2011/08/asynctask.html)
來完成,試試看吧。
我用簡單的網頁 有抓到我要的資料
回覆刪除但是面對較為複雜的網頁 卻怎麼是都抓不到
像是
li class="co130" style="width 143px">
a herf="#" class="ymtvtrigger">
< s p a n class="title now">魔掌
我要抓 魔掌這詞 我寫("class", "title.now", true, false); 但怎抓到不到 也改了[0]這參數 也不行 想問是否是我抓錯了勒?? 還是因為他寫再隱藏標籤 所以不能抓
如果 class="title now" 你就要照著寫 "title now" ,一樣有空白,不要用點。
刪除通常 id 在個頁面中只會有一個(唯一),所以直接抓,傳回的陣列中只會有一個值,所以是 xxx[0] 。
如果是 class 則"可能"會有多個重覆的,所以最好先檢視原始碼,看是在第幾個。但這樣不是很準確,因為有可能發生變動,所在陣列中的位置就會改變。
因此我會縮小範圍,例如有個 div 中有 class="abc" ,那我會先抓到這個 div ,再去取 abc ,這樣在這個 div 之外的 abc 就會被排除。當然,如果這個 div 也有多個,那就要依此類推,去往上做縮小範圍的動作。
另外,你也可以依"標籤"的名稱去抓,去找 getXXXXbyName 的方法,這樣就可以直接抓 span 。抓到最後你想要的標籤,在用 getText().toString() 去秀出值看看是不是你要的。
你提的例子其實可以直接抓 class="co130" 就 getText().toString() ,因為 getText 會忽略其下的除了"文字"以外的所有子標籤。
請問像以下這個網址的內容是不是抓取不到股票的數值? 我看原始檔時, 數值都沒有了. http://money18.on.cc/info/liveinfo_quote.html?symbol=03300
回覆刪除基本上,原始檔有的才能抓到,沒有的當然抓不到。
刪除謝謝TONY, 請問一下, class="quoteNominalRight bigdown2"
刪除OR class="quoteNominalRight bigup2" 這個問題要怎改啊?
我是超級新手, 是不是要用什麼 IF ... ?
那是用來比對網頁原始碼中 class 的名稱,換成你要抓的名稱即可。
刪除Tony, 我是想問,像這個class的名稱會轉變的,要怎麼辦?
刪除class 的名稱應該不會變來變去吧,無論如何就是名稱要符合,才能取得該項目。如果你是指一頁裡面有多個class,但名稱不同,那就是必須每都去抓才行。
刪除作者已經移除這則留言。
回覆刪除請問有沒有辦法抓同屬性但值不一樣的辦法?像下面這樣的形式...
回覆刪除width="61"> x </width...
都是width這個屬性,但有複數個不同的值都想抓取,且依然可以按照網頁的資料順序存放到同一個TagNode[]。
但並不是所有width的值都想抓取,只有特定幾個。
刪除說明書
刪除http://htmlcleaner.sourceforge.net/doc/index.html
也許用 getElementsHavingAttribute() 去把所有有 width 屬性的元素都抓出來,
接著用 getAttributeByName 去取 width 屬性的值,
然後,特定幾個就要自己去想辦法了,
如果你要的元素剛好都在某個元素的範圍內,例如某個 div 之內,那你可以先把這個 div 抓出來,在用前面那個方法去抓就可以了
也就是說,先縮小範圍,再去抓width。
Tony, 買入好幾本書, 還是搞不明白怎麼將htmlcleaner 改成可以在android 4.X 跑, 能不能市請大大把你原有的範例改為可以在android 4.X 跑, 我兩者比對一下, 可能會明白, 拜託大大了.
回覆刪除應該是執行緒的問題,4.X之後,不能把耗時的工作放在 onCreate 中,請把 getData() 移到另一個執行緒去跑,可以參考 AsyncTask (http://blog.tonycube.com/2011/08/asynctask.html) 這篇。
刪除上面的留言,也有人有相同的問題。
不懂怎麼移和修改原本的. 我看了AsyncTask , 我也把getData 分開出去, 然後將getData 獨立存成 . java 的檔案嗎? 大大能不能修改一下, 比較容易了解, 你看我搞了快一年半了.
刪除Tony大大, 能幫忙改一下嗎?
回覆刪除只是把 getData() 移到 AsyncTask 的 doInBackground 中,上面其他人都能做到,不會太難,你一定也可以的,加油吧~~~
刪除感謝Tony大大的分享,有成功抓取資料了
回覆刪除但想請問一下 如果 降 0.2 元 這樣
我只想抓到降0.2不要元這個字可以嗎? 可不可以請大大指點一下 >_<,我是超級新手
好像說的不清楚,意思是.....降0.2元 是在一個class裡面 但我只想抓到降0.2就好,用大大的發法要怎麼抓到呢 ????
刪除把"元"換成空的,
刪除"降0.2元".replace("元","");
OK了,謝謝Tony
刪除我幾乎把所有的留言和連結都看過一次了,真的學到很多
謝謝你用心地回復每一則貼文
您好
回覆刪除我想請問一下我的參數都有改成新的後
數值出來還都是null
後來我用toast去測試
發現連網的部分getHtmlByGet裡面
HttpResponse response = client.execute(get);
HttpEntity resEntity = response.getEntity();
跑到這會錯誤然後跑到catch
manifest再加了一行
也沒什麼用
lib裡面是兩個
android-support-v4.jar
htmlcleaner-2.2.jar
開發版本是用API 19
最低版本我用14
最高版本我用21
不知道會是什麼問題?版本?還是其他問題?
我其他的專案也有類似的問題
Search cra = new Search();
// create HttpClient
cra.client = HttpClientBuilder.create().build();
// run GET Method
(search是這個class的名稱)
當跑到這兩行會強制結束然後跳出
希望大大能夠為我解惑
感謝
可能你的網址傳回來的資料有錯。
刪除看DDMS的Logcat會有錯誤訊息。
你好Tony老師,我想請問一下
回覆刪除為什麼我在建立TagNode 這個物件的時候, 會無法建立呢???
(TagNode cannot be resolved to a type) 系統也沒有要求import....是API版本的問題嗎??
看一下你的"專案"按右鍵->Build Path,有沒有把HtmlCleaner下載的jar 檔加入你的專案。
刪除原來如此! 謝謝!!
刪除作者已經移除這則留言。
回覆刪除作者已經移除這則留言。
回覆刪除1.先知道如何連到PHP網頁
回覆刪除2.再知道如何從網頁取得自己想要的資料